How AI Decision-Making is Improving Enterprise Outcomes
Blog
Share 
Best AWS Services & Practices Every Data Engineer Should Master in 2025: Everything You Need in Your AWS Toolkit
1. Start with Storage Using Amazon S3
Amazon S3 is a secure and reliable storage solution when you are dealing with massive datasets. It's highly scalable, extremely durable, and serves as a foundation for most data workflows. You can depend on it from initial data landing zones to backup archives.
2. Spin Up Power with Amazon EC2
When you need raw computing power for heavy-duty tasks, such as batch processing or running data pipelines, EC2 gives you the flexibility to choose instance types suitable for your workloads. You're in control of the compute environment, which is key for tuning performance.
3. Simplify ETL with AWS Glue
Managing extract-transform-load operations can be messy. AWS Glue resolves this with automated data discovery, code generation, and job orchestration. AWS Glue can support you if you're managing multi-source ingestion and need to clean and prepare your data for use.
4. Query at Speed with Amazon Redshift
Redshift offers the easiest and quickest way to run complex queries against large volumes of structured data. It's perfect for powering dashboards, reports, and business intelligence tools without the drag of traditional databases.
5. Tackle Big Data with Amazon EMR
If your workloads involve distributed computing using Apache Spark or Hadoop, EMR helps you deploy and manage those clusters in a fraction of the time. It is ideal for advanced data transformations and machine learning (ML) workloads, as it integrates easily with other AWS services.
6. Event-Driven Logic with AWS Lambda
Forget provisioning servers to process a few files. Lambda allows you to write lightweight, trigger-based code that responds to data events. It is an efficient serverless solution for processing files as they arrive or triggering downstream processes.
7. Streamline Real-Time Data with Amazon Kinesis
Modern data doesn't always arrive in neat batches; it streams in constantly. Kinesis helps you manage this chaos by capturing, processing, and analyzing real-time data. You can utilize it for use cases such as log monitoring, clickstream analysis, and sensor data processing.
8. Store Fast & Flexible Data with DynamoDB
DynamoDB is a fully managed, serverless database ideal for workloads where speed and uptime are paramount. It provides a NoSQL solution that works best in situations where low latency is essential, such as recommendation engines or personalized content delivery.
9. Keep Your Metadata in Check: Glue Data Catalog
The Glue Data Catalog can be considered as a metadata hub that consolidates information regarding datasets, schemas, and transformations for you. It improves discoverability and governance—two things no engineer should overlook.
10. Coordinate Workflows with AWS Step Functions
As you know, data workflows can span multiple tools, services, and dependencies. AWS Step Functions help you string those steps together into one cohesive flow, complete with retries and error handling. It's a visual way to orchestrate and manage complex processes with clarity and ease.
Best Practices for Using AWS Tools as a Data Engineer
AWS tools are powerful, but knowing what to use isn’t enough; how you use them is what drives real impact. That’s where the best practices for using AWS services come in:
• Scalability: Use services that grow with your data. Enable auto-scaling in EC2, EMR, and Lambda to handle variable workloads.
• Automation: Set up Glue jobs, Lambda triggers, and Step Functions to run tasks without manual effort.
• Security: Encrypt your data (both at rest and in transit) and adhere to least-privilege access with IAM roles.
• Cost Monitoring: Use spot instances, archive old data in S3 Glacier, and monitor costs with AWS Budgets.
• Smart Workflows: Break pipelines into smaller, reusable steps. Use Step Functions for clear orchestration.
• Track & Monitor Everything: Use CloudWatch and CloudTrail to keep an eye on performance, errors, and user actions.
• Organize Metadata: Keep your Glue Data Catalog updated and use clear naming so your data is easy to find and understand.
• Test Before You Trust: Validate your data and test your pipelines with sample loads before pushing to production.
• Document as You Go: You can easily maintain notes on your workflows, data sources, and transformations for smoother teamwork.
Wrapping Up: Why These Services Matter
Tools that enable speed, flexibility, and automation are not just desirable; they're essential. AWS offers a comprehensive toolkit that covers all stages of the data lifecycle. By staying up to date with these services, you not only improve your performance at work but also position yourself to take the lead in a data-driven, cloud-first future.
For data engineers seeking to excel in their roles, it is beneficial to become proficient in at least 10 AWS services. By serving as the foundation for scalable and effective data pipelines, these services help businesses transform unstructured data into actionable insights. Data engineers can significantly contribute to fostering innovation and informed decision-making within their companies by leveraging the potential of Amazon Web Services.
In a world where data is the new currency, data engineers act as the architects of its flow, designing pipelines, transforming datasets, and enabling intelligent decision-making. As businesses scale and real-time data becomes mission-critical, mastering the best AWS services is no longer optional; it's essential. From data ingestion to transformation, storage, and analytics, AWS for developers and data engineers offers a comprehensive suite of cloud tools that AWS provides to build modern, scalable data ecosystems.
Let’s walk through the best AWS services and practices every data engineer should have in their 2025 toolkit.
Related Articles
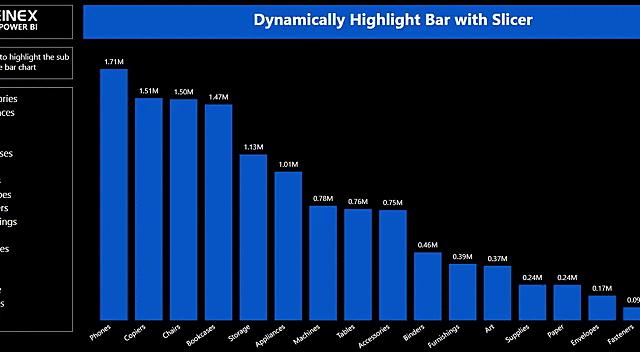
Dynamic highlight bar chart with slicer
But this does not apply to a slicer visual, which only has cross-filtering and no interaction feature. This made me wonder if we can achieve cross-highlight with a slicer visual through some work-around that allows me to compare one category with other easily through cross-highlight.
After some research, I may have found a way to do this. Below are the steps in detail to achieve this.
Normal filtering of data with slicer:
The below example shows normal slicing of data where only the selected value will be reflected in the bar chart. This does not allow me to compare other values easily or focus in on the selected value through highlighting.
 Dynamic highlighting with Slicer:
The below example shows the dynamic highlighting where I can choose the categories in the slicer to highlight for comparison with the other categories. I can easily focus on the selected categories and compare the measure values with other categories.
Dynamic highlighting with Slicer:
The below example shows the dynamic highlighting where I can choose the categories in the slicer to highlight for comparison with the other categories. I can easily focus on the selected categories and compare the measure values with other categories.
 Solution:
First, I have created a disconnected table with the categories. This can be easily done with the following dax formula.
Solution:
First, I have created a disconnected table with the categories. This can be easily done with the following dax formula.
 Added the measure in the field value section.
Added the measure in the field value section.
 Added category slicer from the Selected Category table
Added category slicer from the Selected Category table
 Finally arranged them and saw the magic happen.
Finally arranged them and saw the magic happen.
 Conclusion:
This goes to show the hidden features of Power BI one can explore with a little bit of tinkering with a dash of DAX. This blog is a first in a series of many nifty blogs. Hope you like it and looking forward to your feedback.
Conclusion:
This goes to show the hidden features of Power BI one can explore with a little bit of tinkering with a dash of DAX. This blog is a first in a series of many nifty blogs. Hope you like it and looking forward to your feedback.
Dynamic highlighting with Slicer:
The below example shows the dynamic highlighting where I can choose the categories in the slicer to highlight for comparison with the other categories. I can easily focus on the selected categories and compare the measure values with other categories.
Solution:
First, I have created a disconnected table with the categories. This can be easily done with the following dax formula.
Selected Category = VALUES(Orders[Category])Had made sure there is no relationship in the model view between the source table and new category table. Created a measure which will be added to the conditional formatting in data colour section in the format pane.
Selected Colour bar =
var selected_category = VALUES ('Selected Category'[Category])
var category_to_highlight = SELECTEDVALUE (Orders [Category])
var filtered = ISFILTERED ('Selected Category'[Category])
var result =
SWITCH(TRUE(),NOT(filtered),"#0055cc", category_to_highlight in selected_category && filtered,"#0055cc","#9cd0ed")
return result
Explanation:
Selected Colour bar =
var selected_category = VALUES ('Selected Category'[Category]) // taking values from category table
var category_to_highlight = SELECTEDVALUE (Orders [Category]) // Using selected value function
var filtered = ISFILTERED ('Selected Category'[Category]) // checks if the column is filtered and will return true or false
var result = SWITCH(TRUE(),NOT(filtered),"#0055cc", category_to_highlight in selected_category && filtered,"#0055cc","#9cd0ed")/* The first condition checks if the there is no filtration will return all values, Then will be checking if the selected set of values is contained in the category column. The selected value will be returning a specific dark colour while the unselected value will be giving a lighter colour. */
return resultCreated a bar chart with total sales given in the value section and the category column from the source data will be given as axis. Gave the highlight effect by adding a measure in the field value section of the data colour conditional formatting.
Added the measure in the field value section.
Added category slicer from the Selected Category table
Finally arranged them and saw the magic happen.
Conclusion:
This goes to show the hidden features of Power BI one can explore with a little bit of tinkering with a dash of DAX. This blog is a first in a series of many nifty blogs. Hope you like it and looking forward to your feedback.
Air Navigation and Tableau: Simplifying Complexity
Learn how Tableau has aided the business in finding lucrative new sources of income and ensuring that airport operations run like clockwork even in challenging circumstances.
The pre-Tableau era in Aviation
The aviation industry used to spend a lot of time doing the same operations on a daily, weekly, or monthly basis before Tableau was introduced and used because most of the data processes lacked the ability to be automated. They had to manually enter this information into Excel and re-create the same report each week to give senior management the most recent traffic data from the airport, for example. Additionally, it may be difficult to find key insights buried in spreadsheets of flight and traffic data, which means that sometimes the companies might have missed opportunities to improve their operations altogether.
Tableau as a problem solver
Now that most of these previous manual operations are fully automated, hundreds of man-hours can be saved each month. Data is prepared in Alteryx, staged in SQL server databases, and then connected straight to Tableau, where it can be instantly refreshed. A new dashboard can be created at once, and it will never require manual upkeep or updating again. Because data is available whenever they need it, employees become more independent and can effectively address their own queries and analytics requirements. Different teams, including those in finance, capacity planning, operations, engineering services, investment planning, and more, use Tableau in this fashion.
Because of Tableau's focus on visual analytics, particularly mapping, it is much simpler to spot important patterns and trends in the data, such as newly popular airline destinations. Complex metrics are much easier to comprehend when you have that visual feel of the marketplace. Tableau is made to maximise geographic data, so you can understand both the "where" and the "why." Without the need for specialised software, everyone can conduct geospatial analysis thanks to out-of-the-box geocoding and beautiful interactive maps of Tableau.
Tableau drives new revenue streams
The Business Development team's main goal is to increase airport activity and attract additional airlines. To do this, companies must create a strong business case showing that there are unmet passenger demands. For instance, Tableau discovered sizable passenger traffic volumes that were travelling indirectly through other hubs to Dubai. They were able to identify and develop new market prospects for passengers who weren't previously served thanks to this information.
It used to take a lot of figures to be done crunching to uncover these insights, but today the teams can investigate the data using an automated Tableau dashboard that is updated monthly with ticketing data from the International Air Transport Association (IATA) database. To examine the most recent trends, Tableau can quickly explore the data on a global heatmap. This method saves companies days of manual analytics effort by providing them with the evidence that they need to develop airline offers quickly and persuasively.
Tableau and day-to-day operations
The airports that are open 24 hours a day, 7 days a week, must function flawlessly 24 hours a day. The weather is one of the biggest risks to this since it can abruptly cause serious interruptions. Fortunately, Tableau may be used to lessen the worst consequences. When the meteorological division issues a weather warning, Tableau examines the planned itinerary for the impacted timeframe and looks for airlines that operate several flights to/ from the same location. Then, to lessen the effects of this interruption while maintaining connectivity and customer service standards, Tableau collaborates with these airlines to proactively reschedule or cancel flights and combine the demand with fewer flights.
Beinex being Tableau Premium Partner provide sustainable analytics solutions and help organisations to build superior data visual analytics capabilities internally through our bespoke training programs. We have 100 years of combined experience in Tableau and are led by professionals who have successfully delivered Tableau projects in the region for large private and public sector organisations. Our team of Tableau-certified consultants are real-life Tableau business users who are passionate about Tableau and delivering a world-class experience. We have successfully implemented Tableau in various industrial sectors in the Middle East and in other countries too.
Start a free trial of Tableau. Try now!
Top 4 Ways on How Marketing Leaders Use Alteryx AI & Analytics Automation for Business Success
Four Ways Alteryx Automation and AI Can Transform Your Marketing Strategy:
While there are numerous objectives marketing teams can achieve with data analytics, this blog highlights four ways Alteryx automation and AI can transform your marketing strategy:
1. Centralize Your Data
As the marketing landscape prepares for a cookie-less future, having a unified view of your data is essential. Staying ahead of customer needs, competition, and campaigns requires gathering all your data in one place.
With analytics automation, you can easily integrate data from various sources—whether cloud or on-premises, first-party data, or marketing applications like web analytics and CRMs—to gain a comprehensive view of your customers. This enables marketing teams to react to market shifts in real time.
Use case:
For example, a multinational retailer leveraged analytics automation to bring together data from all customer interactions, resulting in a 37x improvement in processing efficiency. This allowed them to better understand customer behavior across multiple channels.Unlike traditional spreadsheets, which have limitations on data capacity, analytics automation platforms offer limitless capabilities, allowing you to manage vast amounts of customer and product data in one place.
How Alteryx Helps:
• Drag-and-Drop Data Integration: Simplify complex data workflows with easy-to-use, drag-and-drop tools that eliminate manual coding and reduce time to insight.
• Automated Data Cleaning: Utilize pre-built data preparation tools to clean, standardize, and transform data in just a few clicks, ensuring high-quality data for analysis.
• Cluster Analysis: Automatically group similar data points (e.g., customer segments) using clustering tools, enabling precise targeting and personalization without manual intervention.
2. Enhance Your Marketing Campaigns
Marketing success depends on speed and agility, especially when it comes to predicting market trends and competitor behavior. Optimizing targeting, pricing, or strategy without the right insights becomes a challenge. Analytics automation helps you find the right combination of offers and tactics to increase conversions and boost revenue.
Use Case:
A retail chain with 500+ stores struggled to predict customer buying patterns and optimize promotions. By implementing analytics automation, they processed customer data in real time, enabling hyper-personalized marketing campaigns that boosted conversion rates by 35%.
They also used machine learning to predict demand and optimize inventory, preventing stockouts during key promotions. Additionally, they automated pricing analysis, reducing adjustment times from weeks to hours. By integrating spatial analytics, they could identify high-performing stores and strategically allocate resources, further enhancing their marketing and sales efforts. They also automated pricing analysis based on regional market dynamics, reducing adjustment times from weeks to hours and ensuring competitive pricing across all locations.
How Alteryx Helps:
• Predictive Modeling: Leverage machine learning models to forecast demand, optimize pricing strategies, and predict customer churn, allowing for proactive campaign adjustments. • Market Basket Analysis: Identify products that are frequently purchased together to optimize cross-selling and upselling opportunities, increasing revenue per customer. • Real-Time Analytics: Process large volumes of data in real-time to quickly adjust marketing strategies and promotional offers based on current performance metrics. • Spatial Analytics: By analyzing geographic data, marketing teams can optimize store placements, allocate resources more effectively, and improve overall sales performance.
3. Maximize Your Talent and Resources
Many marketing teams struggle to turn data into valuable business insights. According to Gartner, only 53% of marketing decisions are informed by data analytics. Limited staff and time often prevent teams from fully utilizing their data potential.
Analytics automation bridges this gap by enabling teams to achieve more with fewer resources. It automates the time-consuming tasks of data cleaning and preparation, allowing marketing teams to save significant hours and focus on more strategic projects.
Use Case:
For example, a leading digital advertising agency transitioned from using spreadsheets for social media analysis to implementing analytics automation. This resulted in a 99.5% faster analysis, saving 180 weekly analyst hours. By automating routine tasks, your team can dedicate more time to high-impact initiatives, ultimately enhancing overall business value.How Alteryx Helps:
• Self-Service Analytics: Empower non-technical users to perform complex data analyses without relying on IT or data science teams, accelerating time to insight. • Workflow Automation: Automate repetitive tasks like data cleansing, transformation, and reporting, significantly reducing manual effort and minimizing the risk of errors. • Scalable Solutions: Handle vast amounts of data effortlessly, allowing your team to focus on high-impact projects without being bogged down by data management issues.4. Achieve Immediate Results While Preparing for the Future
Marketing leaders often juggle the challenge of balancing short-term returns with long-term strategic goals. Analytics automation solutions can provide quick wins while also laying a foundation for future success.
By choosing a solution that is user-friendly and easy to implement, you can skip lengthy training sessions and start seeing results quickly. Moreover, the best analytics tools are designed with the future in mind, offering integration with cloud services and AI-driven insights.
Use Case:
For example, a premier company specializing in technology services, utilized analytics automation to analyze 250 broadcast campaigns, resulting in an 88% time savings and a 25% increase in time spent on advanced analytics. The right automation tools not only generate fast results but also ensure you're ready for future growth.How Alteryx Helps:
• Quick Implementation: Start generating insights rapidly with intuitive tools that require minimal training. Alteryx’s user-friendly interface means your team can hit the ground running without lengthy onboarding sessions. • Future-Ready Integration: Alteryx seamlessly integrates with cloud services, AI platforms, and advanced analytics tools, ensuring your marketing strategy evolves alongside technological advancements. • Comprehensive Analytics Suite: From spatial analysis to text mining, Alteryx provides a wide range of analytical tools that help you address complex business questions and prepare for emerging trends.
How Marketing Teams Can Benefit from Alteryx
With Alteryx, marketing teams can benefit from:
• Self-Service Analytics: A user-friendly, drag-and-drop interface, you can easily access and analyze data without technical expertise.
• Pre-Built Analytical Tools: Utilize pre-configured tools for market basket analysis, spatial analytics, and more without needing custom development.
• Seamless Integration: Integrate Alteryx with your existing marketing tech stack for a cohesive, end-to-end analytics solution.
Alteryx+ Beinex Offerings
Our Premier partnership with Alteryx empowers business users to automate manual data cleansing and transformation tasks in minutes through a simple visual workflow while incorporating the latest technological advancements.
Connect with us for a free demo: https://beinex.com/alteryx-partner/
The Transformative Power of AWS Cloud Infrastructure Services
AWS and Pay-as-you-go Model
AWS adopts a pay-as-you-go model for the majority of its cloud services. This means you pay only for the specific services you use, for the duration of your usage, and without the need for lengthy contracts or intricate licensing agreements. The pricing structure is akin to paying for utilities such as water and electricity – you are charged solely for the services consumed, and once you cease using them, no additional costs or termination fees apply.
The pay-as-you-go system with AWS ensures that you pay only for the resources your organisation utilises, promoting agility, responsiveness, and scalability. This approach allows you to effortlessly adjust to evolving business requirements without committing to fixed budgets, ultimately enhancing your ability to respond to changes promptly.
In essence, paying for services on a needed basis empowers your organisation to focus on growth and efficiency rather than getting bogged down by unnecessary expenses.
Let’s understand the key benefits AWS customers can reap from embracing AWS Cloud Infrastructure services, unlocking a world of possibilities for organisations seeking to transform their operations and drive unparalleled value.
AWS Economic Overview: Realizing Significant Savings
An economic analysis by the Enterprise Strategy Group highlights that migrating on-premises workloads to AWS results in substantial savings and benefits across various categories:
- Cost Optimization and Improved Operational Efficiency
- Faster Time to Value and Improved Business Agility
- Reduced Risk to the Organization
1. Cost Optimization and Improved Operational Efficiency
By transitioning to AWS Cloud Infrastructure, organisations shed the complexity and burden associated with on-premises operations. This shift allows IT infrastructure teams to focus on business innovation rather than managing hardware, creating a ripple effect that enhances the efficiency of application, development, and data service teams. The move to AWS results in simplified administration, automated tasks, and substantial time savings, with reported efficiencies ranging from 60% to 70%.
a. Designed for Best Price-Performance: Employing Customized SolutionsAWS's commitment to delivering the best price-performance for many applications and workloads is evident in its continuous innovation. From the Nitro System and AWS Graviton processors to AWS Trainium and Inferentia accelerators, AWS has engineered custom silicon that optimises performance and efficiency, allowing organisations to achieve cost savings while enjoying top-notch performance.
b. Financial Flexibility, Predictability, and Visibility: Enabling Decision-MakingAWS offers a transparent monthly billing model, shifting organisations from up-front capital investments to a more flexible and predictable cost structure. With tools like AWS Cost Explorer, customers gain visibility into resource utilisation and identify cost-saving opportunities. Flexible purchase models, including On-Demand Instances, Spot Instances, and Savings Plans, provide financial flexibility, enabling organisations to meet infrastructure needs while staying within budget constraints.
c. Managed Services: Enabling Business TransformationAWS-managed services not only free up internal teams from infrastructure maintenance but also allow them to scale operations using fully managed services. By reducing administrative burdens through offerings for monitoring, incident detection, security functions, and more, organisations can focus on delivering superior data services and business logic. The AWS Partner Network (APN) further enhances this capability, offering a global community of partners to collaborate with and derive greater business value.
d. Improved Environmental Sustainability: A Commitment to a Greener FutureAs environmental, social, and governance goals take centre stage, organisations benefit from AWS's global infrastructure to lower their carbon footprint. Moving from on-premises to AWS Cloud Infrastructure can lead to a significant reduction in electricity consumption and associated costs. AWS's commitment to powering operations with renewable energy aligns with the sustainability goals of organisations, contributing to a greener and more responsible future.
2. Faster Time to Value and Enhanced Business Agility
Embracing change can be challenging for any IT organisation, particularly for large enterprises deeply invested in on-premises technology. Overcoming hurdles such as standardising organisational structures and adopting best practices adds complexity to the transition. However, AWS offers a compelling solution, guiding organisations seamlessly through the shift from on-premises environments to the cloud. This transition not only occurs swiftly and securely but also brings about a significant improvement in business agility, unlocking outcomes that were previously unattainable.
a. Faster time to migrationTransitioning on-premises workloads to AWS Cloud Infrastructure enables organisations to swiftly leverage modern end-to-end data architectures. This facilitates immediate benefits in storing, protecting, analysing, visualising, and extracting valuable insights from data. Remarkably, a customer successfully migrated their business applications to AWS in a single weekend, involving over 200,000 business customers and 400 internal users across three global locations.
AWS, as a cloud provider, offers a comprehensive range of services and features within those services, making the process faster, easier, safer, and more cost-effective. Whether rehosting workloads or relocating entire data centres, AWS empowers organisations to build virtually anything, providing confidence through proven phased methods, assessment tools, and mobilisation support.
AWS stands out by delivering unique capabilities and technologies that enable customers to experiment and innovate rapidly. The cloud infrastructure allows customers to benefit from continuous innovation in modern computing, networking, and storage technologies without needing on-premises forklift refreshes.
Technologies like the AWS Nitro System, Amazon FSx for Lustre, and various deployment options empower organisations to modernise applications, accelerate development, and explore edge computing solutions seamlessly. AWS connects containers and microservices with application-level networking, secure API gateways, and advanced tools for modernising or re-platforming applications.
The AWS Global Infrastructure facilitates secure, extensive, and reliable global cloud operations. Customers can seamlessly deliver data, applications, and services to regions worldwide while meeting SLAs. Leveraging AWS Direct Connect, customers can run applications using on-premises and cloud resources without compromising performance, ensuring private, secure connections bypassing the internet.
AWS tools and services enable the transformation, enrichment, and accessibility of data for diverse workloads such as AI, ML, HPC, and BI. Customers experience improved data-driven services, efficient access for remote workers through AWS Client VPN, and high-performance applications at the edge using CDN services like Amazon CloudFront.
AWS empowers organisations to scale computing, networking, and storage resources swiftly in response to changing business demands. With minimal planning, customers can provide additional resources in minutes, starkly contrasting the weeks or months required on-premises. Leveraging AWS Auto Scaling and intelligent optimisation tools, customers ensure predictable, steady performance while optimising costs.
Enhanced scalability allows for dynamic adjustments to resource capacity, saving developers significant time in manual infrastructure maintenance and scaling. Customers can precisely provision resources, proactively reducing infrastructure costs, and flexibly choose from 600 compute instances to meet workload requirements. This flexibility extends to running applications on VMs, containers, or serverless services, enabling deployment options across geographic regions, data centres, or at the edge.
Reduced Risk to the Organization
In prioritising security, AWS is a trusted partner for organisations, addressing concerns related to data protection, service interruptions, data corruption, compliance, and malicious intent. Security holds paramount importance in the design of the AWS Global Infrastructure, custom-built for the cloud and continuously monitored to ensure the confidentiality, integrity, and availability of customer data.
a. Comprehensive Security Measures:Protection at all levels, including physical security, infrastructure security, network backbone security, and data security. Rigorous access controls, encryption, retention, and auditing to meet compliance requirements. AWS’s commitment to ongoing investments in security technologies and operational best practices.
b. Shared Responsibility Model:Security and compliance shared responsibility between AWS and the customer. AWS manages components from the host operating system to physical security, while customers handle the guest operating system, application software, and AWS security group firewall configuration.
c. Data Protection and Security:AWS offers built-in security features at the chip level through the Nitro System, ensuring continuous monitoring and verification. Virtualisation resources are offloaded to dedicated hardware and software, minimising the attack surface. The security model of the Nitro System is locked down to prevent administrative access, reducing the risk of human error and tampering. AWS provides tools for data resiliency, including snapshots, versioning, and full backup and recovery solutions.
d. Secure Access Control and Operations:AWS customers have tools for securing access, including a centralised firewall, AWS Identity and Access Management, encryption features, and more. Features like Amazon S3 Object Lock, checksums, replication, and versioning ensure data integrity. Protection against exploits and DDoS events with AWS Web Application Firewall (WAF) and AWS Shield.
e. Improved Compliance:AWS customers receive tools and visibility to demonstrate compliance locally and regionally. AWS CloudTrail helps organisations avoid penalties for regulatory non-compliance.
f. Data Sovereignty and Privacy:Organisations retain control over data storage, security, and access. AWS ensures data remains within chosen AWS Regions and is committed to confidential computing. Specialised hardware and firmware protect customer code and data from external access.
Summing Up
Embracing AWS Cloud Infrastructure services is not just a technological upgrade; it's a strategic move that unleashes innovation, enhances efficiency, and aligns businesses with the future of digital transformation. The transformative journey with AWS goes beyond cost savings; it's about realizing the full potential of technology to drive growth, agility, and sustainability in an ever-changing landscape. As organisations navigate the complexities of the digital age, AWS stands as a trusted partner, offering a robust foundation for a future-ready enterprise.
A DEEP DIVE INTO TABLEAU 2019.3
TABLEAU CATALOG
What could be better than a feature that could provide better visibility and better data management at the same time, and also ensure that the right data is always used for analysis. This is possible with the new feature -Tableau Catalog.
 This feature provides a complete picture of the data and how each data is connected.
Another use of Tableau Catalog is linear and impact analysis. This not only shows which assets will change but also who will be affected by it, which makes work easier for many and avoids wastage of time.
EXPLAIN DATA
Tableau 2019.3 is up with a new Al-driven feature called the “Explain Data”, which helps people go from the “what” of the data to the “how” of it. With explain data, we can get an explanation for each unexpected value in the data by just a single click. On selecting the desired data point, the ‘explain data’(lightbulb) icon appears.
For each value there might be a number of explanations. Each of these explanations are checked and only the most likely ones are provided as visualizations.
This feature provides a complete picture of the data and how each data is connected.
Another use of Tableau Catalog is linear and impact analysis. This not only shows which assets will change but also who will be affected by it, which makes work easier for many and avoids wastage of time.
EXPLAIN DATA
Tableau 2019.3 is up with a new Al-driven feature called the “Explain Data”, which helps people go from the “what” of the data to the “how” of it. With explain data, we can get an explanation for each unexpected value in the data by just a single click. On selecting the desired data point, the ‘explain data’(lightbulb) icon appears.
For each value there might be a number of explanations. Each of these explanations are checked and only the most likely ones are provided as visualizations.
 Now these visualizations can be used for further explorations.
TABLEAU SERVER MANAGEMENT ADD-ON
Organizations that run critical deployment of Tableau Server at a large scale, have mentioned concerns over manageability and scalability. They have been in search for tools that could organize the management process in an efficient way, which could save a lot of time. Tableau solved this problem by introducing the Tableau Server Management Add-on – a new feature designed to help organizations manage the deployment of Tableau Server. With this, they can quickly react to the changing needs of the business as well as save time by organizing the management process in the most efficient way. Tableau Server Management Add-on, which makes running the critical deployment of tableau at a large-scale server much simpler.
Now these visualizations can be used for further explorations.
TABLEAU SERVER MANAGEMENT ADD-ON
Organizations that run critical deployment of Tableau Server at a large scale, have mentioned concerns over manageability and scalability. They have been in search for tools that could organize the management process in an efficient way, which could save a lot of time. Tableau solved this problem by introducing the Tableau Server Management Add-on – a new feature designed to help organizations manage the deployment of Tableau Server. With this, they can quickly react to the changing needs of the business as well as save time by organizing the management process in the most efficient way. Tableau Server Management Add-on, which makes running the critical deployment of tableau at a large-scale server much simpler.
 The server management add-on feature can help in optimising the performance of deployment by customizing which nodes process background jobs such as extract refreshes and subscriptions and isolating these workloads, to specific nodes. This makes it easier to scale deployments to the needs of their organization.
This feature has a few tools, including two for better reliability and scalability and one for content migration, all of which helps the organizations to govern their data effectively.
If you are interested in learning more about the latest Tableau release and use cases, please contact us at training@beinex.com/ info@beinex.com and we would be happy to schedule a Tableau demo or training for you and your company.
The server management add-on feature can help in optimising the performance of deployment by customizing which nodes process background jobs such as extract refreshes and subscriptions and isolating these workloads, to specific nodes. This makes it easier to scale deployments to the needs of their organization.
This feature has a few tools, including two for better reliability and scalability and one for content migration, all of which helps the organizations to govern their data effectively.
If you are interested in learning more about the latest Tableau release and use cases, please contact us at training@beinex.com/ info@beinex.com and we would be happy to schedule a Tableau demo or training for you and your company.
This feature provides a complete picture of the data and how each data is connected.
Another use of Tableau Catalog is linear and impact analysis. This not only shows which assets will change but also who will be affected by it, which makes work easier for many and avoids wastage of time.
EXPLAIN DATA
Tableau 2019.3 is up with a new Al-driven feature called the “Explain Data”, which helps people go from the “what” of the data to the “how” of it. With explain data, we can get an explanation for each unexpected value in the data by just a single click. On selecting the desired data point, the ‘explain data’(lightbulb) icon appears.
For each value there might be a number of explanations. Each of these explanations are checked and only the most likely ones are provided as visualizations.
Now these visualizations can be used for further explorations.
TABLEAU SERVER MANAGEMENT ADD-ON
Organizations that run critical deployment of Tableau Server at a large scale, have mentioned concerns over manageability and scalability. They have been in search for tools that could organize the management process in an efficient way, which could save a lot of time. Tableau solved this problem by introducing the Tableau Server Management Add-on – a new feature designed to help organizations manage the deployment of Tableau Server. With this, they can quickly react to the changing needs of the business as well as save time by organizing the management process in the most efficient way. Tableau Server Management Add-on, which makes running the critical deployment of tableau at a large-scale server much simpler.
The server management add-on feature can help in optimising the performance of deployment by customizing which nodes process background jobs such as extract refreshes and subscriptions and isolating these workloads, to specific nodes. This makes it easier to scale deployments to the needs of their organization.
This feature has a few tools, including two for better reliability and scalability and one for content migration, all of which helps the organizations to govern their data effectively.
If you are interested in learning more about the latest Tableau release and use cases, please contact us at training@beinex.com/ info@beinex.com and we would be happy to schedule a Tableau demo or training for you and your company.
Note: The Server Management Add-on is not available for Tableau Online, as they manage everything from scaling, performance, and security on behalf of their Tableau Online customers. The Tableau Server Management Add-on can be separately purchased from the Tableau Server deployment.